前回、並列階層に対する概念的な説明をしましたが、今回は読者の皆様に具体的なイメージをつかんでいただくため、誤解を恐れず大胆に数値を仮定してシミュレーションをしてみることにします。結果の様子はできるだけよくある状況に合わせたつもりですが、個々の数字などはそのまま一人歩きされると困るものばかりですのでご注意ください。
第19回(リンク)に説明したベクトル(SIMD)演算器や、本ブログの主題であるマルチコア、最近話題になることが多いチップレットなど、世の中には様々な並列実行ハードウェアがあります。
今回は、ベクトル演算器やSIMD演算器の例についてあげ、関連技術としてNVIDIA社のGPGPUについても簡単に紹介します。
前回紹介したベクトル(SIMD)演算器に向けたコンパイル技術が自動ベクトル化です。自動ベクトル化は自動並列化(第16回(リンク)参照)と似たような概念であり、広い意味では自動ベクトル化は自動並列化の一部ですが、狭い意味では異なります。
今回はベクトル演算、SIMD演算の話です。ベクトル演算とSIMD演算は並列計算としては同種の高速化で、配列計算の一括処理です。マルチコアとは別の概念ですが、重要な並列技術ですのでこのブログでも取り上げたいと思います。
EdgeTech+2024 TOPPERSブースにおいて「組込みマルチコアコンソーシアムが見る組込み産業の課題」と題して枝廣が講演しました。 講演では、当コンソーシアムの紹介、およびSDVに代表される今後の組込みシステムの方向性と課題について話し、その中での取り組みと今後の活動についてお話しました(組み込みマルチコアコンソーシアム 会長 枝廣正人)。...
例年、EMS 組込みマルチコアサミット)を開催してきましたが、今年は少し形をかえて実施します。 11月21日(木) 13:40-14:10(予定)パシフィコ横浜にて開催されるEdgeTech+2024において 「組込みマルチコアコンソーシアムが見る組込み産業の課題」と題して枝廣が講演します。 詳しくは以下の記事をご参照下さい。
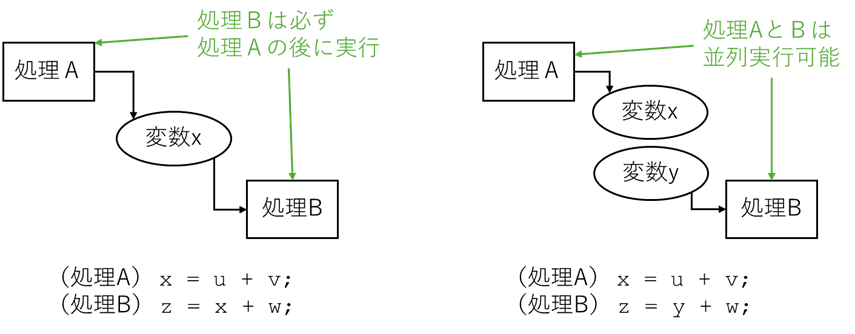
掲題についてchatGPTを用いて作成した例を紹介します。なお例において、関数呼出の箇所で関数をインライン展開することにより依存の有無が判定できる場合もありますが、ここではコンパイラはそこまでのことをしないことを前提としています。また、文中に「静的」という言葉がでてきますが、コンパイラのようにプログラムを動作させることなく解析することを静的解析といいます。
コンパイラはプログラムを動作させることなく解析するため、実行時にならないとわからない情報の解析には限界があります。その代表例がC言語のポインタです。ポインタの値はOS等が割り当てるメモリ番地であるため、実行時にならないとわかりません。以下で詳しく説明しますが、ポインタを利用(特に演算)すると、処理の依存関係(データの読み書き順序などの理由で生じる処理の実行順序関係)の解析が難しくなり、2つの処理A、Bの依存関係が不明という状況が生じます。
シングルコア向けに書かれたソフトウェアを自動的にマルチコア向けにコンパイルするツールが自動並列化コンパイラです。 前回の動画で紹介したMBP (Model Based Parallelizer) (https://www.esol.co.jp/embedded/product/embp_overview.html )はMathworks社のSimulinkモデルを入力とする自動並列化ツールです。C/C++言語プログラムなどからの自動並列化ツールとしては、Intel社のコンパイラ...