
コンパイラはプログラムを動作させることなく解析するため、実行時にならないとわからない情報の解析には限界があります。その代表例がC言語のポインタです。ポインタの値はOS等が割り当てるメモリ番地であるため、実行時にならないとわかりません。以下で詳しく説明しますが、ポインタを利用(特に演算)すると、処理の依存関係(データの読み書き順序などの理由で生じる処理の実行順序関係)の解析が難しくなり、2つの処理A、Bの依存関係が不明という状況が生じます。本来、処理AとBには依存(実行順序の制約)がなく、並列に処理できるにもかかわらず、コンパイラの解析で不明になってしまうと、コンパイラは処理AとBを並列実行せず逐次的に実行する選択をせざるを得ないため、並列性能が下がってしまいます。
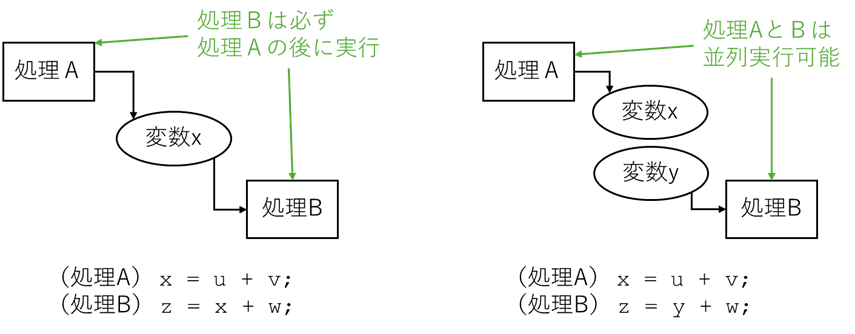
ポインタの話をする前に依存関係(正確にはデータ依存関係)について具体的な例を用いて説明します。依存関係とは、例えば下図左のように複数の処理が同じ変数に対して読み書きしており、その実行順序が結果(この場合には変数zの値)に影響するような場合をいいます。依存関係は並列化に重要な影響があり、この例の場合には処理Bは処理Aよりも必ず後に実行される必要があり、処理AとBは並列処理できません。下図右のように読み書きする変数が異なれば結果に影響することがなくなり、処理AとBは並列処理が可能になります。そのため、最大の並列性能向上を得るためには処理の依存関係を減らすことが重要です。依存関係を減らすためには、当然ながら処理のアルゴリズムにおいてできるだけ依存をなくすことが肝要ですが、今回は、依存関係が存在しないにも関わらずコンパイラの解析によって依存があるかもしれないと判断されてしまうケースについて考えます。
変数として配列を用いると解析が難しくなります。下の例について考えてみます。この例では上図の例の変数xとyの代わりに配列要素S[i]とS[j]を用いています。この場合にはiとjの値が同じならば依存関係があって処理AとBは並列化できず、異なれば並列化可能になります。上の例では変数名で解析可能でしたが、下の例では変数名(i, j)に加え、変数が持つ値の解析まで必要ですので話が難しくなります。コンパイラでは性能よりも結果の正しさが重視されるため、iとjの値があらゆる状況において異なることが保証できなければ「依存関係あり」としてコード生成するため並列化しません。大規模ループ構造を分割して並列実行できると高い性能を得られることが多く、かつ、ループ構造内では配列処理が多用されるため、配列要素の解析は極めて重要です。例えば1から100までのforループにおいて、ループ変数はループ回転ごとに異なる値になることは明確ですが、不必要に異なる変数を導入し、配列要素に使って解析を複雑にするようなことは避けることが望まれます。

ポインタを使うとさらに話が複雑になります。ここでは代表例であるC言語のポインタについて説明しますが、配列を記述できるどのようなプログラム言語においても配列要素のメモリ番地を変数として表現する方法があれば同様の話になります。
C言語のポインタは配列要素の参照として頻繁に使われます。ポインタ解析(特に配列要素の参照として使われた場合)については古くから研究されており、少しずつ解析可能なケースは増えていますが、現在のところ完全とは言えません。コンパイラにおいて解析が困難になるポインタ利用の例として、間接的なポインタの計算、エイリアシング(同じポインタ変数で異なるポインタを使い回す)などがあげられます。上述の配列を用いた例においても、S[i]とS[j]をポインタで表現し、モジュール化や計算量削減等を目的としてポインタの計算をすると、コンパイラによる依存関係解析が困難になってしまう状況が起こりえます。iとjの値の一致性と2つのポインタの値の一致性は同じ難易度のように思えますが、実際にはOS等が実行時に決めるメモリ番地(コンパイル時には不明)を使って計算することになるため、ポインタ解析の方が難しくなります。例えば、プログラム論理上はまったく関係ない二つの大域的なポインタ変数の値も、OS等が実行時に割り当てる値であるため、それぞれ計算した値をメモリ番地としてメモリの読み書きを実施したときに、あらゆる場合にメモリ番地が一致しないことの証明がかなり困難になる場合があります。C言語で配列要素参照にポインタを使用すると依存解析が困難になる場合についてchatGPTを用いて作成した例について次回紹介します。
さて、ここまで説明してきた話の本質は、ポインタが指すメモリ番地が不明になるということであり、アルゴリズム通りに計算ができているのかわからなくなることです。つまりソフトウェア品質の低下につながります。逆に言えばソフトウェア品質向上は並列性能向上にもつながります。
前々回の動画で紹介したMBP (Model Based Parallelizer) (https://www.esol.co.jp/embedded/product/embp_overview.html )は、依存関係をモデルから抽出するため、プログラムコードを解析するよりは精度が向上する傾向があります。下図左にモデルの例を示しますが、矢印によって依存関係が明記されます。それにより並列化した結果が中図(色はコアごと)で、右図が並列実行の様子です(色はタスクごと)。しかしモデルにおいてもメモリ要素を定義することができ、モデルの様々な箇所からアクセスすると解析が難しくなります。

ソフトウェア品質向上のための規則(車載開発をターゲットとしたものではMISRA C規格やJMAABのモデリングガイドライン)に則った開発は、自動並列化コンパイラの利用を前提とした将来のソフトウェア開発におけるシステム性能向上にもつながる可能性が高いと考えています。

コメントをお書きください