
今回はマルチコアで動作するソフトウェアについて説明します。
マルチコアといっても、GPUなどを使うヘテロジニアス・マルチコアについては概念が異なってくるので別の機会に譲り、今回はCPUマルチコアについてのみ考えます。
CPUマルチコアで動作するソフトウェアを書くことは、第10回(リンク)で説明した図(下に再掲)をプログラムにすることになります。これを並列化プログラミングとよびます。下の図で、上段はソースコードでのイメージと依存関係のグラフ、中段はシングルプロセッサにおける実行、下段はマルチコア上での実行イメージで、黒く塗りつぶした四角はコア間通信です。並列化プログラミングは、上段のプログラムから下段の実行になるようにすることです。なおここで、マルチコア上での実行には、静的スケジューリングにより各処理の実行コアまで決める方法と、OSなどの動的スケジューリングに任せる方法とがあり、下では簡単に区別します。
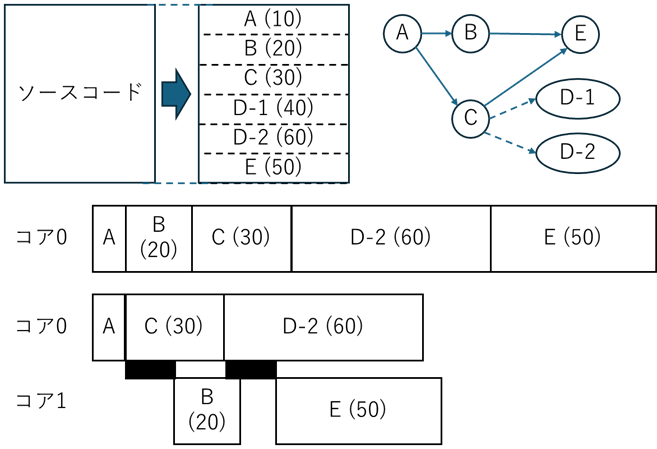
マルチコアで動かすには、まずプログラムを分割する必要があります。ここでは、分割についてはすでに完了しており、上の図の下段のイメージまであることを仮定します。
このとき、分割された実行単位(上図のA~E)のことをタスクやスレッドとよびます。タスクやスレッドの詳細な定義は標準仕様ごと、あるいはOSごとに異なるので、実装する際にはドキュメント等でよく理解しておくことが重要です。
分割後、各処理をマルチコア上の実行単位として定義します。
AMP型で静的スケジューリングを行う場合の最も簡単な方法は、例えば上記の例で処理Aをコア0に割り付ける場合、if (コア番号==0) {処理Aの記述}のように修正する方法です。コア番号の取得方法は実行環境ごとに異なりますが、多くの場合、ユーザーレベルで取得可能になっています。すべての処理について記載し、すべてのコアで同じプログラムを動かせばその通りに動きます。この方法は簡単でOSレスのような場合に見られますが、運用は難しくなります。特にOS上で複数アプリケーションが動作する環境の場合、複数コアを効率よく動かそうとするOSの邪魔をしてかえって全体性能を悪化させる場合もあるので注意が必要です。
OSなど基本ソフトウェア環境を用いている場合にはタスクやスレッドとして書くことが一般的です。RTOSのタスクや、POSIXのpthreadのように処理を関数化して書く方法、C/C++向けのOpenMPのように処理単位を中括弧{}で括って指示行で指定する方法など様々です。もともとシングルプロセッサ上でマルチタスクとして開発されていたシステムであれば、そのまま移行できる可能性もあります。
OSの機能を使っていれば、静的にも動的にもスケジューリングできることが多いです。静的の場合はタスクやスレッドにコア番号を指定(アフィニティとよばれることもある)します。同一コア上の複数処理を一つのタスクやスレッドにまとめ、スケジューリングを固定しつつオーバーヘッドを減らす方法もあります。動的の場合には、そのままOSにスケジューリングを任せます。スケジューリングポリシを指定できるOSもあります。実行環境によってはタスクやスレッドの動作を可視化するツールを利用でき、CPU利用率などを確認することも可能です。
次に、コア間通信を記載します。
コア間通信についても、OSレス環境などでは、共有メモリを排他しながら通信するプログラムを自作することもありますが、一般的にはOSなどが提供する通信ライブラリを用います。特に、コア間通信は排他制御を含むため本質的にデッドロックなどの不具合が起こりやすい部分ですが、OSが利用する排他制御と自前の排他制御が混在すると思わぬトラブルに巻き込まれやすいため、注意が必要です。
なお、動的スケジューリングではどの依存関係がコア間に跨がるのかわからないため、すべての依存関係を陽にタスク(スレッド)間通信として書き、通信ライブラリ内で動的に実行することになります。この場合、基本ソフトウェアとの連携が重要となるため、システムが提供する通信ライブラリを使った方が、開発面でも性能面でも効率がよくなることが多いです。こちらも、もともとマルチタスクプログラムとして記載してあれば、タスク間通信として記載されているはずですので、そのまま移行できる可能性もあります。ただし、優先度によって順序を規定し、その順序を信じて排他制御を入れずに共有メモリを通してデータを受け渡している場合等、マルチコア上動作では不具合が起こるケースがあり、注意が必要です。優先度制御とマルチコアの問題については、別の機会に説明しようと思います。
静的スケジューリングは実行中にスケジューラが動作しないので実行効率は良くなりますが、将来コア数が変更されたときにコア間通信位置が変わるため、プログラムの再利用性は悪くなります。

コメントをお書きください