
前回、一つのアプリケーションの例を用いてマルチコア性能向上の概算手法について説明しました。今回はシステムになったとき難しくなる理由について説明します。
前回の概算手法は、下の図のような実行に対し、各処理の実行時間と、コア間通信やループ並列化のオーバーヘッドの値が既知であるとして計算する手法でした。最初にそれらの値の取得について考えてみます。なお、下の図において黒塗りの四角がコア間通信です。
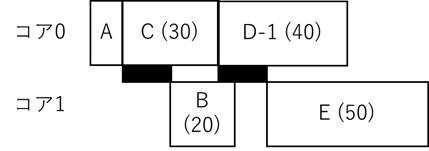
まず、各処理の実行時間ですが、値の取得にはプロファイラを利用する方法やSHIMから計算する方法などが知られています。シングルコアプロセッサでも同様の難しさがありますが、ハードウェアの動的要因(キャッシュ等)による性能変動や、入力データによるループ回転数や条件分岐の変動があり、処理の実行時間は変動します。マルチコアシステムになると、他のコアで別のアプリケーションが動いている場合、その状況によってメモリアクセス時間が異なるといった問題が加わります。
次に、コア間通信オーバーヘッドやループ並列化の前処理、後処理にかかる時間の取得ですが、これらの値がどこかのドキュメントに記載されているようなことはまずありません。コア間通信にかかる時間は、組込みプロセッサ上で簡易なフラグ通信を実装すると数十~数百サイクル、高級OSの安全な通信ライブラリを使うと数千サイクル以上といった感覚はあるものの、実装に依存するため実際には実行環境の上で実験して取得する必要があります。また、これらの値も、前回の概算では一定としましたが、処理到着順等の影響で変動し、かつ実行時間と同様、マルチコアシステムの場合、メモリまわりの混雑度による変動が大きくなります。
このとき並列性能向上について考えます。前回の概算では、各処理の実行時間と、コア間通信やループ並列化のオーバーヘッドの値によって処理の並列実行(コア割当とスケジューリング)が決まり、並列性能向上が計算できました。依存関係によってできる空き時間を別の処理で埋めることにより効率の良い並列実行を実現するため、変動の影響により期待と異なる結果になることが多々あります。例えば前回の例では、コア間通信オーバーヘッドが70を超えるとすべての処理を同一コアで実行することが最適になりましたが、設計時に50と見積もって並列化した後、実際に実行してみると70を超えた場合、並列化せず単一プロセッサ実行の方がよかった、といった結果になります。
さらに、複数アプリケーションが存在するシステムの場合、上述のように他コアで動くアプリケーションの影響でCPUバス等の状況が変わり、メモリアクセス時間が変動します。また、処理の実行周期や優先度を考慮した基本ソフトウェアのスケジューリングポリシ等も影響し、概算することすら困難になります。
そのため、前回の最初の話題に戻り、マルチコアで性能はどのくらいあがるのか、という質問に対しては、ターゲットアーキテクチャ(ハードウェアと基本ソフトウェア)における処理の実行時間や各種オーバーヘッドの値が得られれば個々のアプリケーションについて概算は可能、といった回答になるでしょう。
複数アプリケーションからなるシステムはもちろん、単一アプリケーションであっても上述の値の取得が難しい場合や精度が高い解析が必要な場合には、マルチコアアーキテクチャや基本ソフトウェアのシミュレータのようなツールを用いることが一般的であり、それゆえやってみないとわかりません、といった回答になりがちなのです。

コメントをお書きください