
今回からパイプライン並列化を始めます。
パイプライン並列化とはどのような並列化でしょうか。
私はCコンパイラを作っていたので、CPUの命令(アセンブリ言語です)には馴染みがあります。
そこで、CPUの命令を例にしてみます。
RISC-CPUが出現した時に、それまでのCISCと区別し始めました。
RISCの機械語(アセンブリ命令)は単純な作りで、命令サイズも同じ、命令速度も全命令が1サイクルで動作する。だから速い。ざっくり言うと、こんな感じの説明が見られました。
実際には、RISC命令ひとつずつは1サイクルでは動作しません。しかし、命令をいくつかのステージに分けて処理することで、その命令の終了ポイントを見れば確かに1サイクルずつ命令が進んでゆくように見える。そういう手法で高速化しています。
良くあるRISC命令の動作説明図は、こんな感じでした。
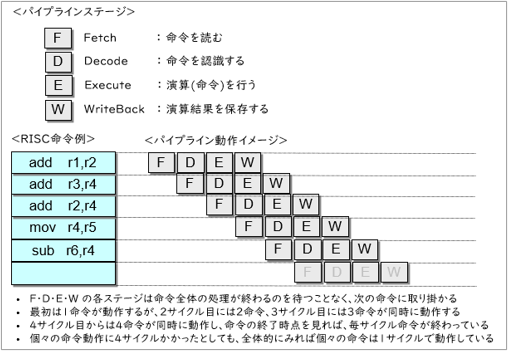
パイプライン並列化は、プログラムをこの図のようにいくつかのステージ処理に分解して階段的に動かし、勢いに乗った時には全ステージが同時に動くような構造の並列化です。
これを実現するためには、まずステージの分割が必要です。
- 各ステージは後続ステージが使うデータを壊さないように次のデータを処理しなければならない
- 各ステージの処理時間ができるだけ同じであることが望ましい
この並列化のために、プログラムを以下の4ステージに分けました(4色のステージに分割)。
各ステージは、Sub_PickUp・Sub_Mult1・Sub_Mult2・Sub_AddChk の4つの関数です。

EMC組み込みマルチコアサミット2020、セミナー資料より
4つのステージに分割した処理をそれぞれ2つずつ8個のスレッドで動かしてみます。
それぞれのステージはキューで繋ぎます。キューの中に必要な処理データが入っています。
プログラムは以下の構成で、main関数が4ステージ×2の関数をスレッドとして起動します。
スレッド間はキューで連携し、キューをアクセスするための en_que と de_que という関数も作ります。

EMC組み込みマルチコアサミット2020、セミナー資料より
このプログラムには、以下のように階段的なパイプラインによる並列処理を行ってくれることを期待しています。
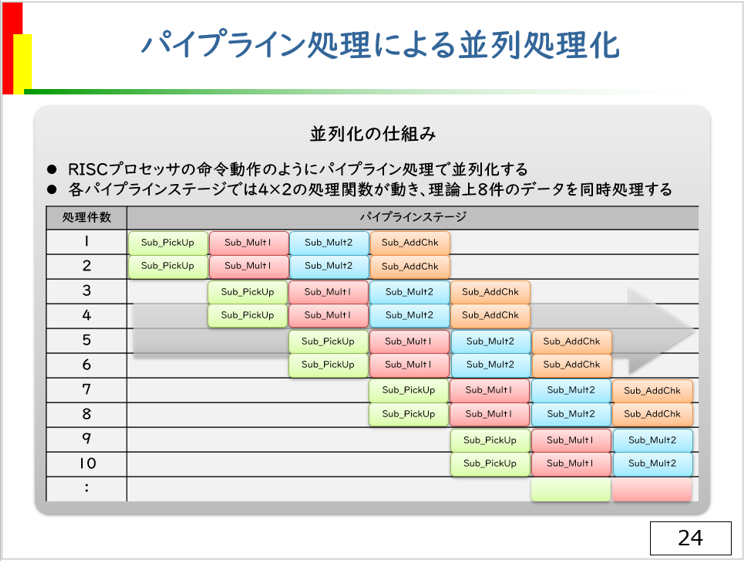
EMC組み込みマルチコアサミット2020、セミナー資料より
次回は、このプログラムの驚きの動作結果について説明します。
2. Source_Program_3.h (Source_Program_3.cが使用するインクルードファイル)

コメントをお書きください